Guide current as of June 11, 2026. Fable 5 is included on Pro/Max/Team plans through June 22; usage credits apply after. Latest news →
ClaudeFieldGuide › Benchmarks
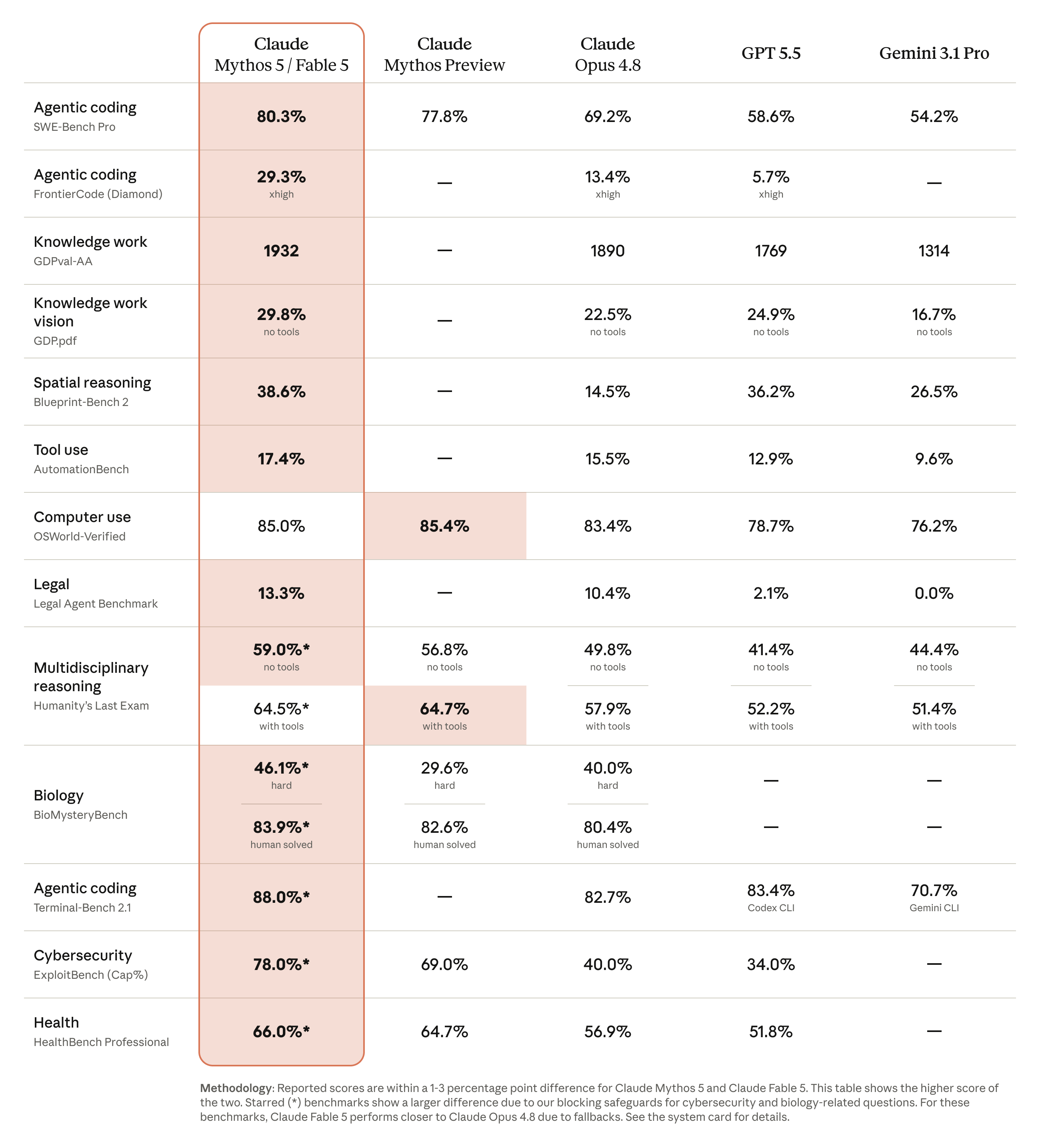
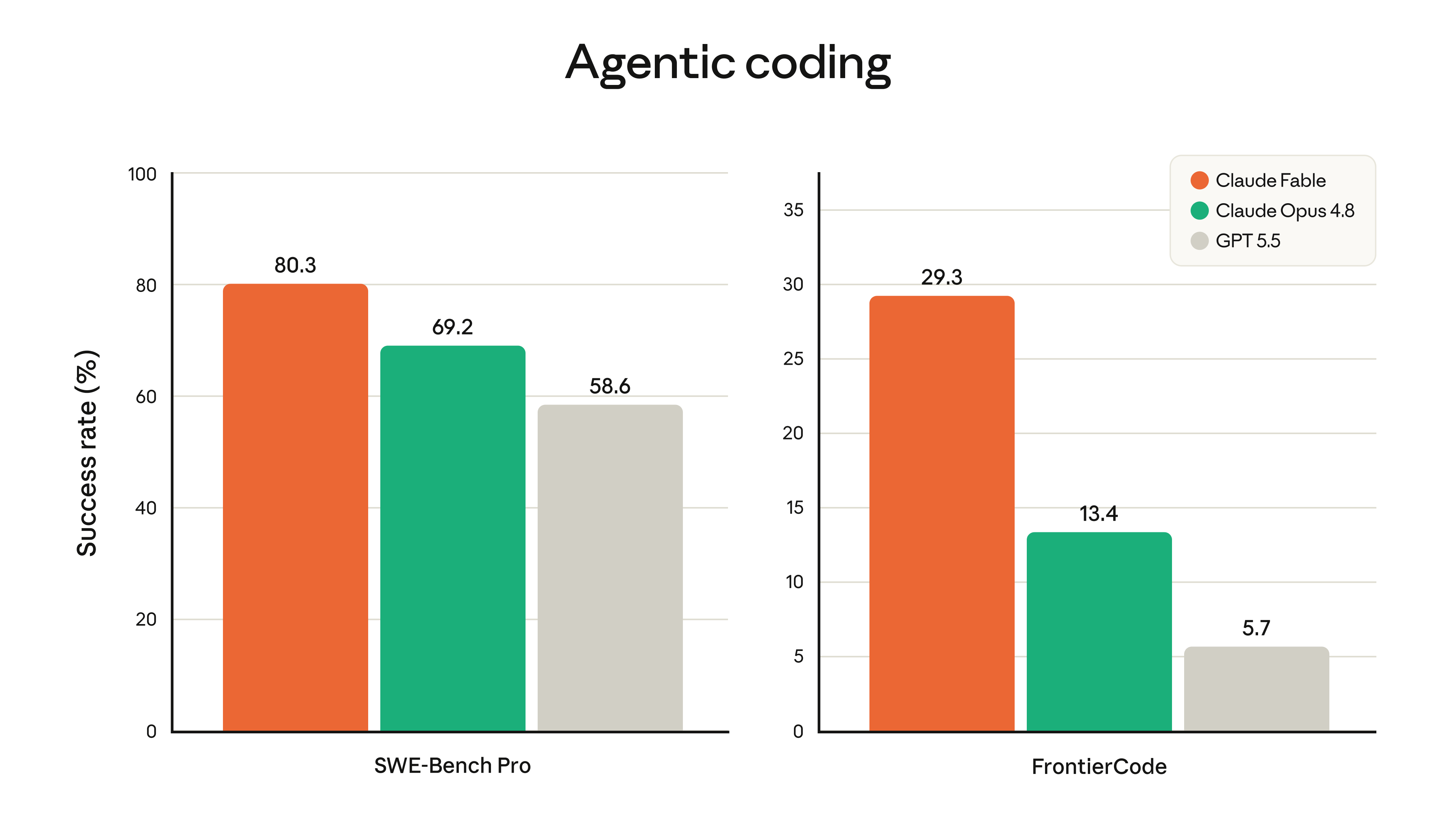
Software engineering
| Claim | Source |
|---|---|
| 50-million-line Ruby migration completed in one day (team scoped two months) | Stripe, via announcement |
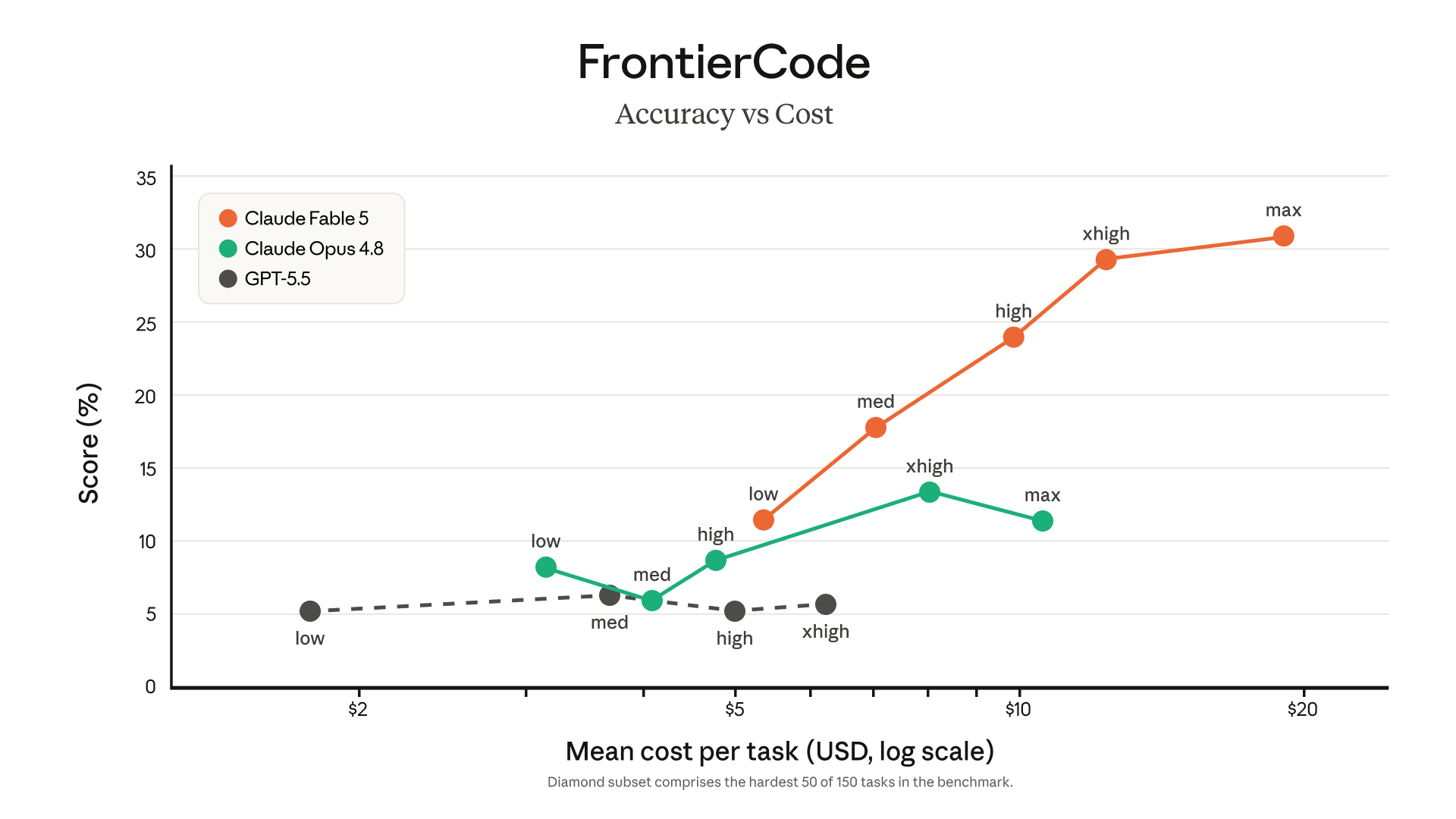
| Highest frontier score on FrontierCode — at medium effort (chart, chart 2) | Cognition |
| "State of the art model on CursorBench" | Michael Truell, Cursor |
| Long-horizon autonomy "exceeded previous benchmarks" | Mario Rodriguez, GitHub |
| Highest on ViBench end-to-end vibe-coding, "nearly saturating base use cases" | Michele Catasta, Vibe |
{kind=link}
{kind=link}
Knowledge work & research
| Claim | Source |
|---|---|
| First past 90% on core analytics benchmark — 10 points over Opus; top of Finance Benchmark | Izzy Miller, Hebbia |
| "Aced trading-analysis evaluations nearly across the board" | IMC |
| Strongest on frontier physics at a third of the reasoning tokens; in 36 hours reached "nearly" where GPT-5.5 landed in four days (partner report, not an independent eval) | Matthew Pines, Notation Capital — via announcement, June 9, 2026 |
Vision, memory, autonomy
| Claim | Source |
|---|---|
| Completed Pokémon FireRed vision-only with a minimal harness | Announcement |
| Rebuilds web-app source from screenshots; extracts precise values from scientific figures | Announcement |
| With file memory in Slay the Spire: improved 3× more than Opus 4.8; reached final act 3× more often | Announcement |
Independent results (early — day two)
| Claim | Source |
|---|---|
| #2 of 123 models, 96/100 overall, on the provisional leaderboard; top-tier coding and agentic scores; #18 on multimodal/grounded (79) — the first independent wrinkle in the vision story | BenchLM |
| 95.0% on SWE-Bench Verified | Reported via BenchLM aggregation |
| AA-Omniscience knowledge benchmark: 40 — seven points above the previous leader, Gemini 3.1 Pro | Artificial Analysis, via Simon Willison |
| 91/100 on Every's internal senior-engineer exam (Opus 4.8: 63) | Every, via AI+ Founders |
| Guardrail fallback observed on ~8–9% of tasks (mostly scientific) — vs the announced <5% session average; methodology differs (tasks vs sessions), flagged as the launch's most checkable open question | The Decoder |
| Sustained 12-hour autonomous runs | Digital Today |
Early and provisional — leaderboards move in week one. Tracked in News.
Mythos research results
Run with safeguards lifted, by vetted partners — context on the Mythos page:
| Claim | Source |
|---|---|
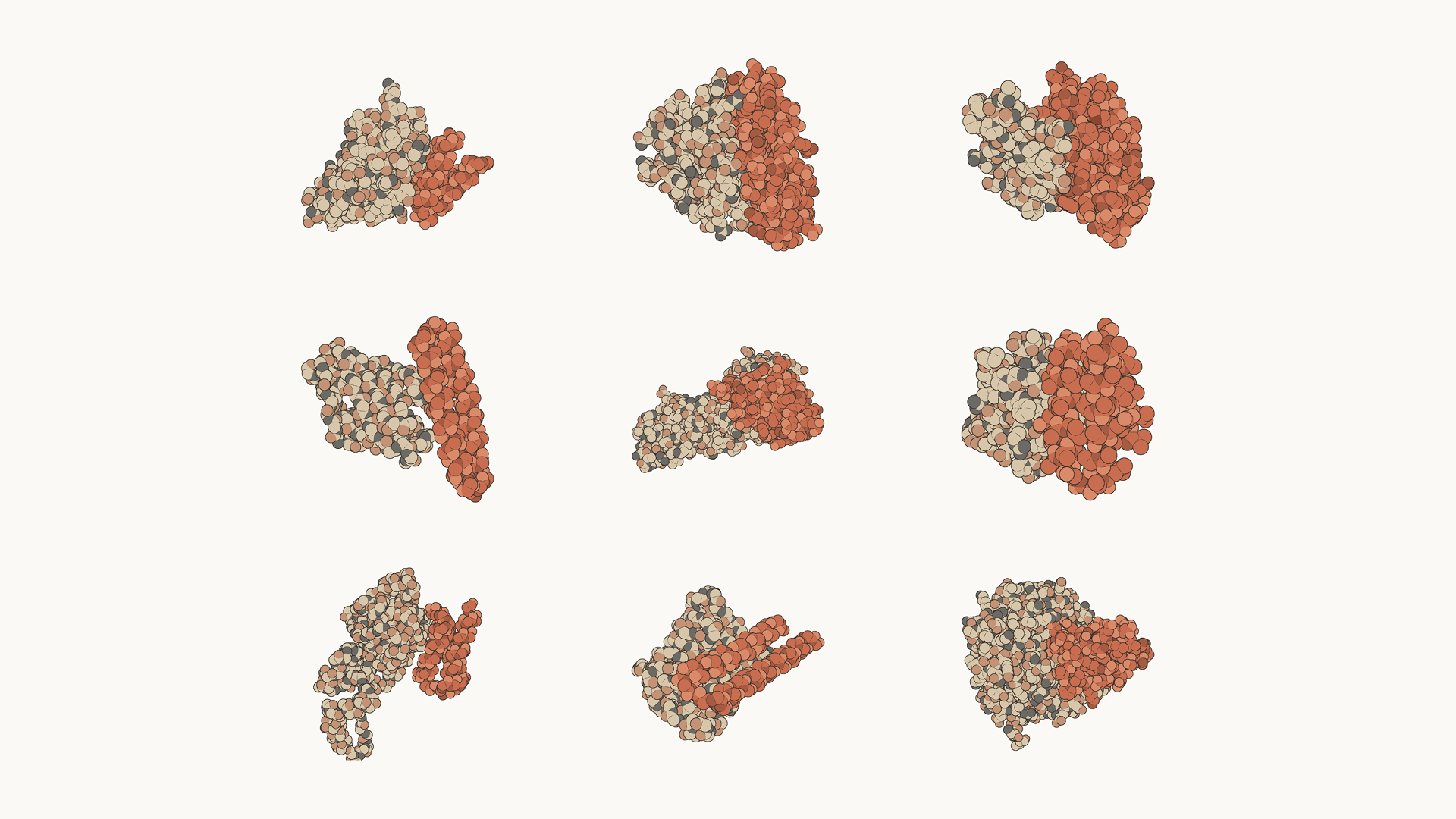
| ~10× acceleration on aspects of drug design; 9 of 14 protein targets yielded strong candidates (chart) | Announcement |
| Hypotheses preferred ~80% over Opus-class in blinded comparisons; one corroborated independently | Announcement |
| Genomics model beat a recent Science publication at 1/100th the size, from a week-long autonomous run | Announcement |
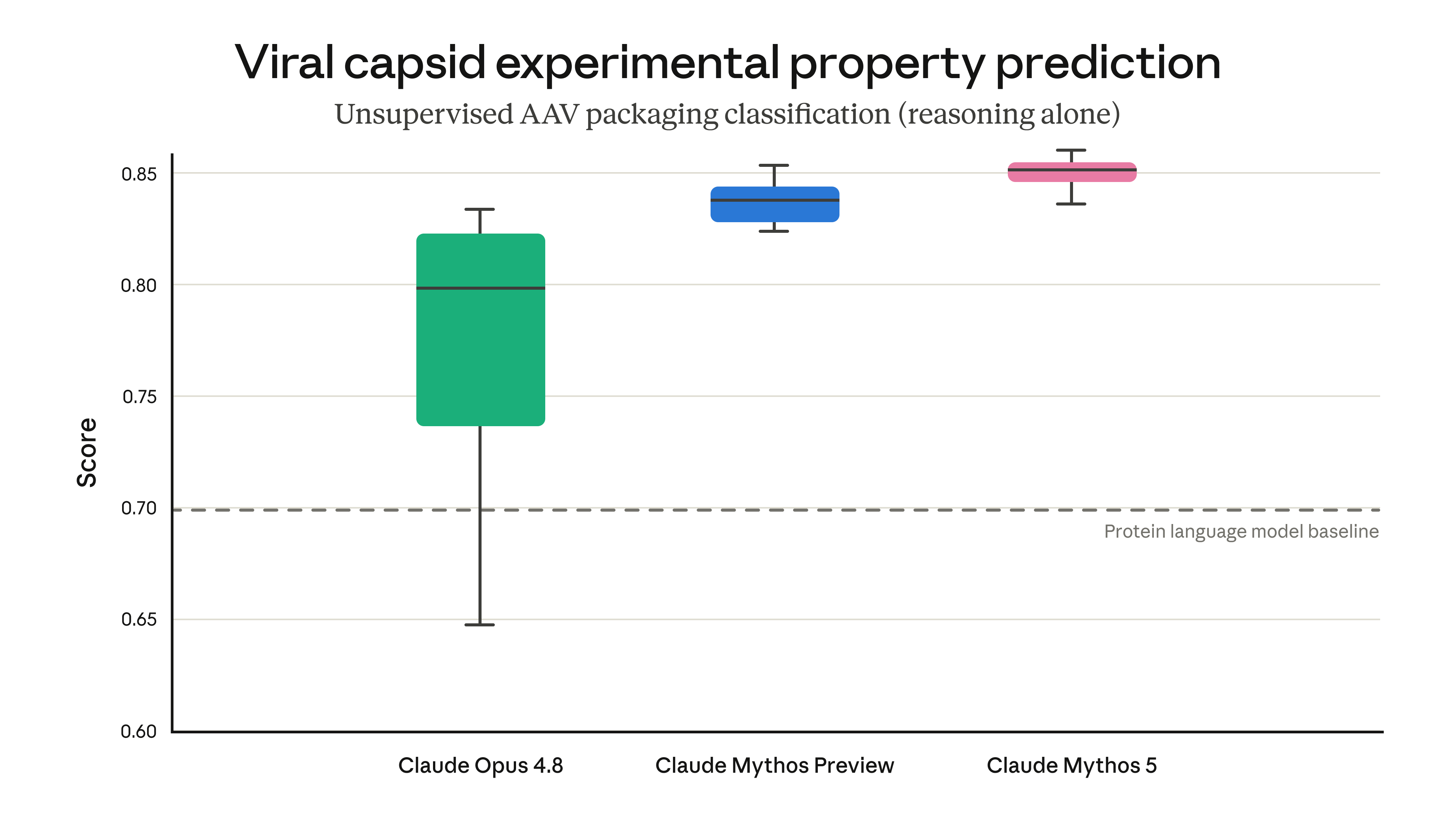
| Beat dedicated protein language models on AAV prediction (chart) | Announcement |
{kind=link}
{kind=link}
Reading the wall: everything above is launch-day material — Anthropic's own numbers and partner quotes from the announcement. Independent third-party evals get their own section here as they publish. If a claim has no receipt, it doesn't go up.